
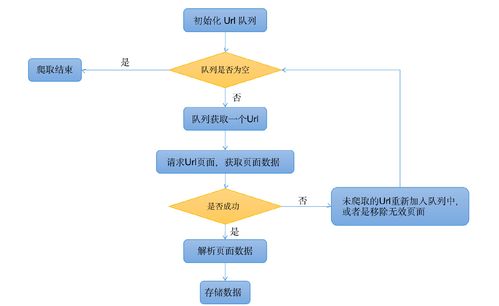
服务端爬虫生成API是一种自动化工具,用于创建和管理网络爬虫。它允许用户通过简单的界面或编程接口定义数据抓取规则,从而无需手动编写复杂的代码即可从网站收集信息。这种API通常提供数据提取、处理和存储功能,便于开发者快速实现数据集成和分析。
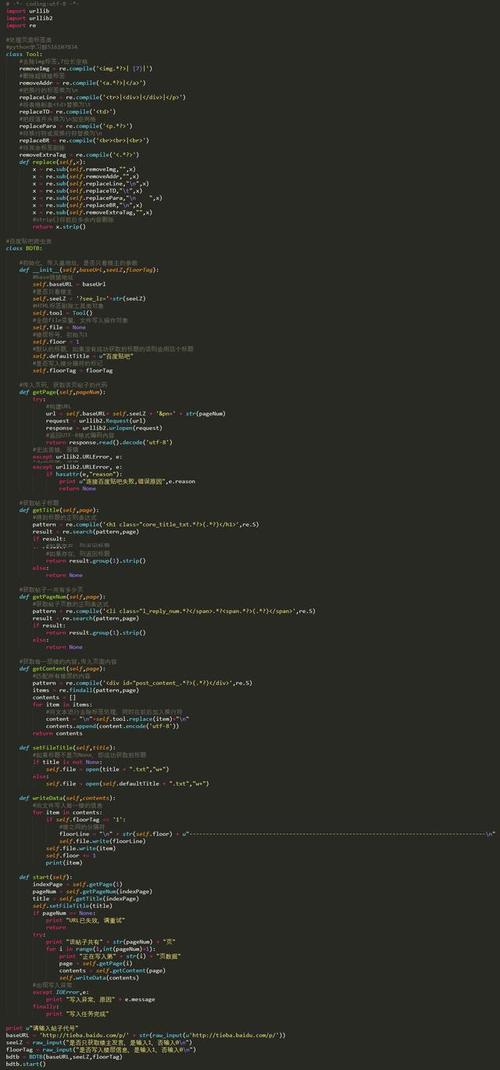
要生成一个服务端爬虫的API,你需要遵循以下步骤:

(图片来源网络,侵删)
1、选择一个编程语言和框架,Python和Flask或Node.js和Express。
2、安装所需的库和依赖项,Python的requests库和BeautifulSoup库。
3、编写爬虫代码,从目标网站抓取数据。
4、将抓取到的数据进行处理和清洗。
5、创建一个API接口,以便客户端可以通过HTTP请求访问这些数据。
6、部署API到服务器上,使其可以被外部访问。
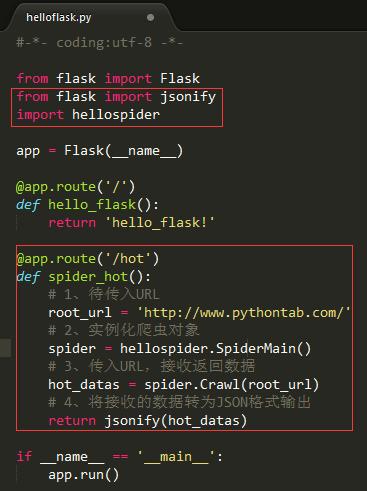
以下是一个简单的Python和Flask示例,用于创建一个爬取网页内容的API:
from flask import Flask, jsonify
import requests
from bs4 import BeautifulSoup
app = Flask(__name__)
@app.route('/api/crawl', methods=['GET'])
def crawl():
url = 'https://example.com' # 替换为你想要爬取的网站URL
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取所需数据,这里以提取所有段落文本为例
paragraphs = [p.text for p in soup.find_all('p')]
return jsonify({'paragraphs': paragraphs})
if __name__ == '__main__':
app.run(debug=True)
在这个示例中,我们创建了一个名为/api/crawl的API接口,当客户端向该接口发送GET请求时,它将返回一个包含目标网站所有段落文本的JSON对象,你可以根据需要修改这个示例,以适应你的爬虫需求。
(图片来源网络,侵删)
(图片来源网络,侵删)
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

