
MapReduce是一种在大规模数据集上执行分布式计算的编程模型,它通过将计算任务分为两个阶段——Map阶段和Reduce阶段,从而实现对数据的高效处理,下面将详细分析MapReduce的执行过程,并提出相关的思考问题。
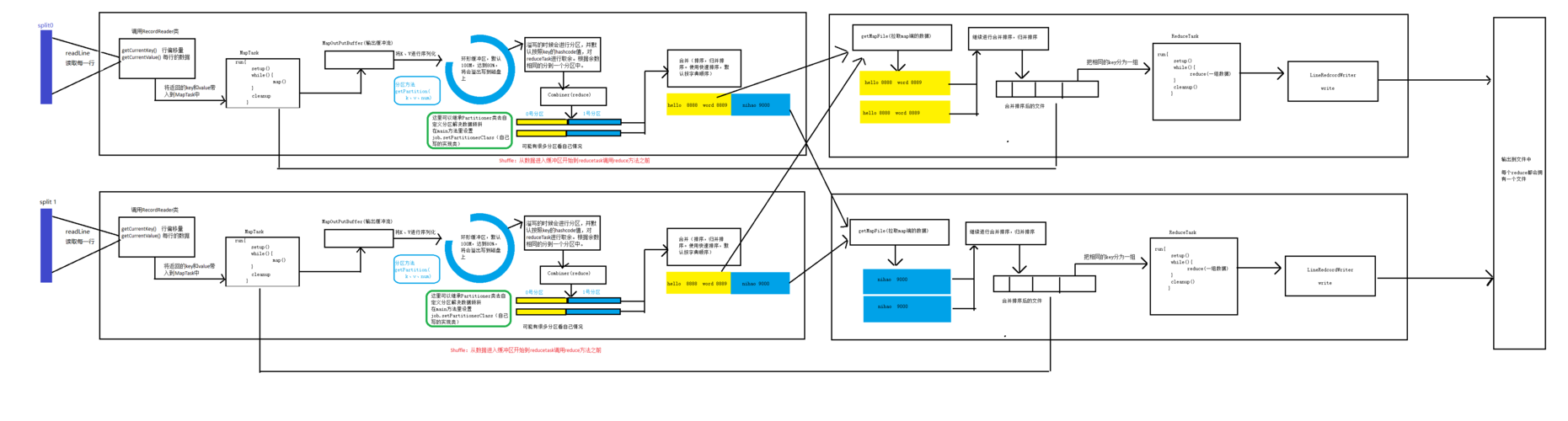

1、数据输入与分片
数据输入的准备:在MapReduce框架中,数据首先需要被存储在HDFS(Hadoop Distributed File System)中,这是因为HDFS能够可靠地存储大量数据,且提供高速的数据访问速率。
分片操作:输入数据会根据配置的大小(Hadoop 2.x中的默认大小是128MB)被划分成多个数据块,即分片(split),每个分片将由一个Map任务处理,而格式化操作则负责将这些分片转换成键值对<key,value>的形式,其中key通常代表数据的偏移量,value则是分片中的数据内容。
2、Map阶段的执行
Mapper任务的处理:每个Mapper任务是一个独立的Java进程,它读取HDFS中的文件,并将其解析为一系列的键值对,这些键值对经过用户自定义的map方法处理后,输出为新的键值对。
中间数据的排序与分区:Map任务完成后,其输出的键值对会根据key的值进行排序,并可能进行分区(partition),以准备Reduce阶段的数据聚合。
3、Shuffle和Sort阶段
数据准备:Map输出的数据需要在网络中传输到Reduce任务所在节点,这个过程被称为Shuffle,在这个过程中,系统还会对数据进行Sort,以确保Reduce端可以有效地处理数据。
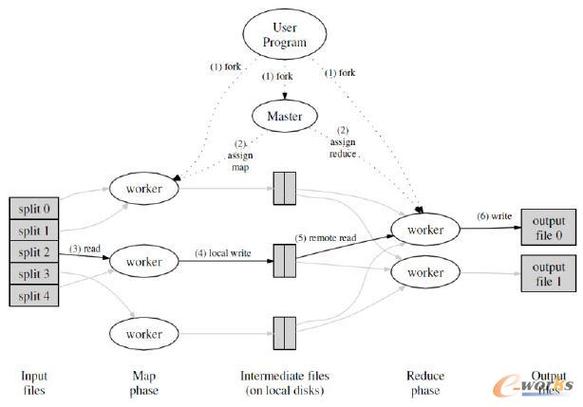
4、Reduce阶段的执行
Reducer任务的处理:每个Reducer任务接收来自Mapper任务的输出作为自己的输入数据,并根据这些数据调用自定义的reduce方法来进行处理,最终的输出结果将被写回HDFS中。
5、作业的完成
作业监控与完成确认:在整个过程中,用户可以监控程序的执行情况,并在必要时中止作业,一旦MapReduce作业完成,用户可以使用HDFS命令查看结果或者进行下一步的数据分析工作。
通过上述详细分析,可以看到MapReduce通过分布式处理大大提高了数据处理的效率,值得注意的是,合适的分片大小、优化的数据格式以及有效的容错机制等因素都会影响到MapReduce作业的执行效率,接下来提出两个与本文相关的问题,并进行解答。
Q1: MapReduce框架如何提高系统的容错性?
A1: MapReduce通过多种机制提高系统的容错性,每个Map或Reduce任务在不同的节点上运行,避免单点故障影响整个作业的执行,MapReduce会有机制监测每个任务的执行情况,一旦发现某个任务失败,会自动重新调度该任务到其他节点执行,中间数据和最终结果都会存储在HDFS中,即使任务失败也不会导致数据丢失。
Q2: 如何优化MapReduce作业的执行效率?
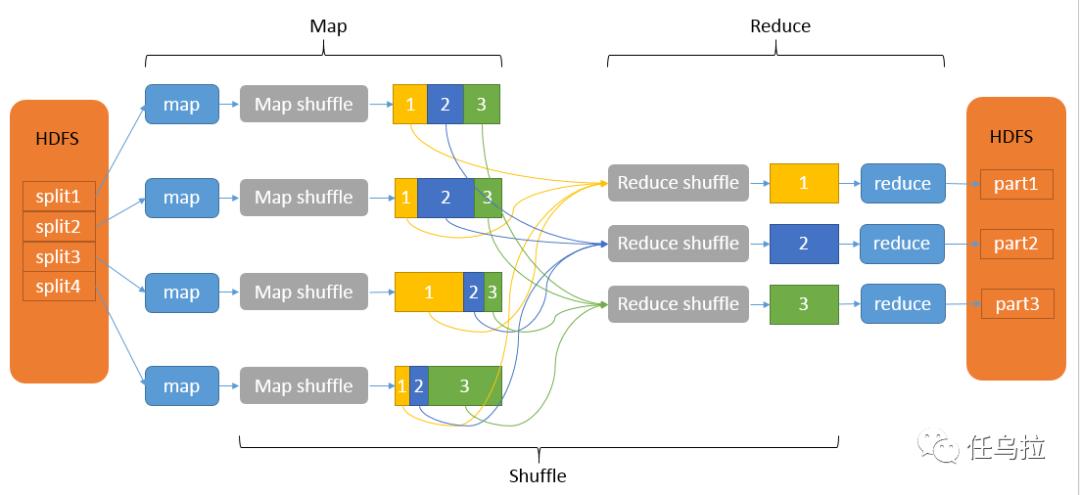
A2: 优化MapReduce作业的执行效率可以从以下几个方面考虑:一是合理设置分片大小,过大或过小的分片都可能影响处理效率;二是优化数据格式和序列化方式,减少数据传输的开销;三是合理设计Map和Reduce函数,避免不必要的计算;四是使用Combiner和InMem Sort等技术减少数据处理量和提升数据处理速度;五是合理配置硬件资源,确保网络带宽和存储IO不会成为瓶颈。
MapReduce作为一种强大的分布式计算框架,通过简化分布式程序的设计和提高系统的容错性,极大地方便了开发者处理大规模数据集,通过适当的优化措施,可以进一步提高MapReduce作业的执行效率,使其在处理海量数据时更加高效。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

